Pragmatic Lakehouse Architecture — Part 2 of a Series
Converge, Diverge, Virtualize — from concept to implementation
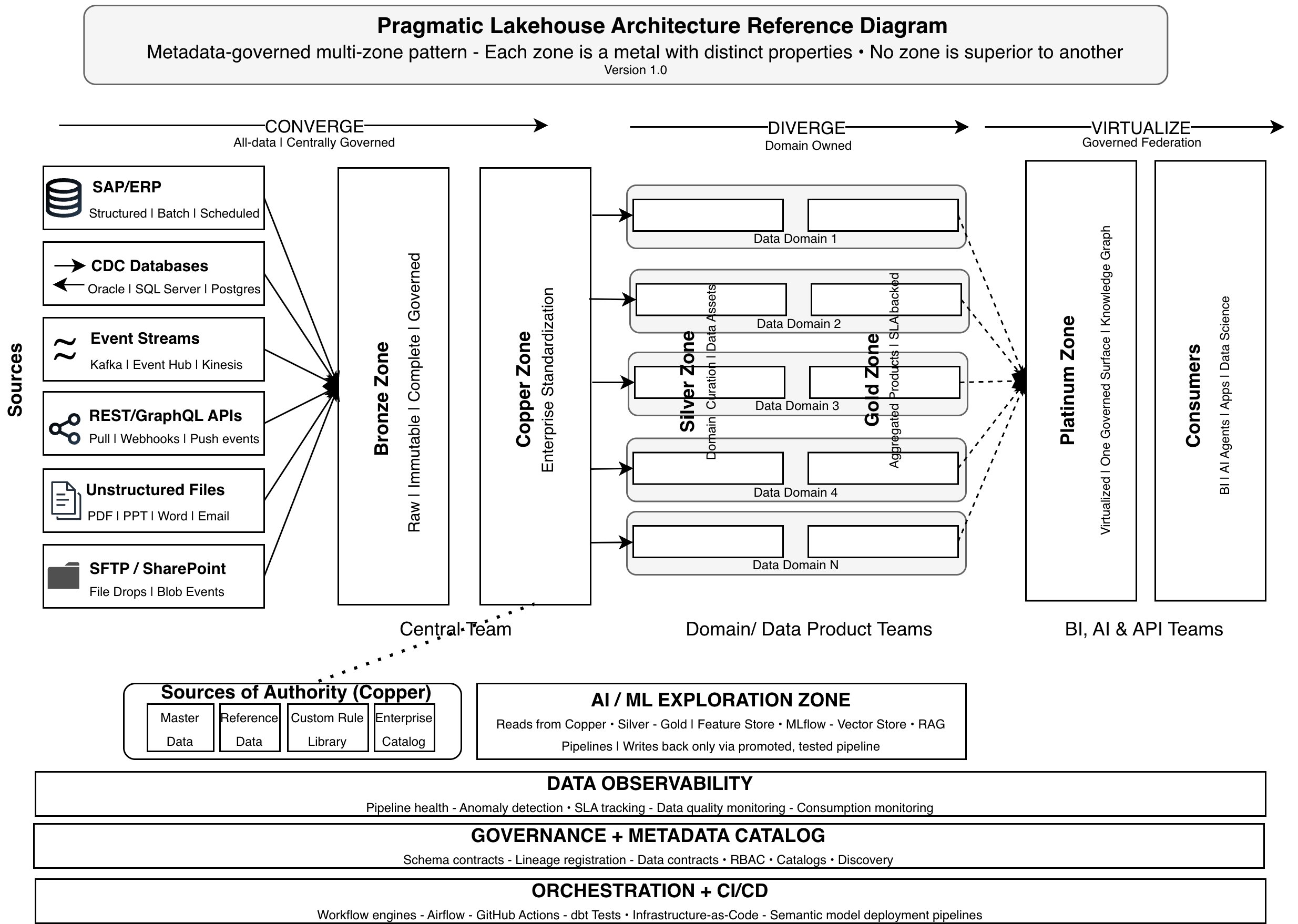
Part 1 opened with a CEO who wants a Daily Sales Report by seven o’clock every morning. Eight weeks later it still does not exist — not because of technology, but because the same metric means three different things across three business units, two platforms, and two recognition policies. The METAllion™ Pattern established the zone structure and the metadata governance mechanism. The CDV Principle explains the governing philosophy that makes the whole pattern work in practice.
The CDV Principle organizes the five METAllion™ zones into three phases, each applying the right organizational model at the right stage. Where to centralize. Where to give autonomy. How to federate. And critically — how security and AI are embedded at every stage rather than configured afterward.
The Converge phase covers Bronze and Copper. Its purpose is to establish a clean, governed foundation before domain teams touch the data. Everything that happens in Diverge and Virtualize depends on the quality of what Converge produces.
Bronze receives data exactly as the source produces it — raw, immutable, complete. The ingestion pattern at Bronze is a choice driven by source system capabilities. Where source systems support open table formats — Delta Lake, Apache Iceberg — data can land directly in a format readable across platforms without an additional copy step. Where they do not, traditional ETL or ELT pipelines ingest into raw storage.
Copper does two things. First, it classifies every field in the enterprise catalog — data type, sensitivity level, source identifier. Second, it enforces enterprise-agreed standards through the four sources of authority: the enterprise catalog, master data, reference data, and the custom rule library. These four sources drive every pipeline rule at Copper. Type casting, reference data validation, master data checks, and sensitivity-driven security rules all originate here and propagate downstream as metadata contracts. Domain teams inherit both the clean data and the security policy. Neither needs to be reconfigured at Silver, Gold, or Platinum.
The Diverge phase covers Silver and Gold. Domain teams own their data products. They apply the business logic that makes data meaningful within their context — joins, business rules, deduplication, aggregations. They publish data products with signed contracts that downstream consumers can depend on.
Domain-specific analytics are served directly from Gold. Supply Chain reporting on its own inventory. Finance analyzing its own P&L. This is the right pattern, not a compromise. Not every analytics requirement is an enterprise requirement. The Diverge phase delivers domain value without the overhead of cross-domain federation.
But when the question crosses domain boundaries — total revenue across all business units, by region, by fiscal quarter — Diverge alone cannot answer it. Each domain knows its own numbers. None has the authority to define what those numbers mean for the whole enterprise. That is when the CDV Principle moves to its third phase.
The Virtualize phase presents one governed consumption surface across all diverged domain data products. Data stays where it lives — in each domain’s platform, in each domain’s storage. The Virtualize phase connects to those data products through shortcuts, live federation, or governed replication depending on what the platform stack supports, and presents them as one unified surface with one set of enterprise metric definitions.
In practice, the Virtualize phase is implemented through a semantic model built on top of the federated data — with Row-Level Security (RLS) and Column-Level Security (CLS) applied. RLS restricts what rows a consumer can see based on their role. CLS restricts which columns are visible. Both are defined once in the semantic model and enforced automatically for every consumer, human or AI, without reconfiguration at each zone.
For AI agents, the Virtualize phase is where trustworthy answers become possible. An agent querying domain data directly encounters column names without context, metric definitions without governance, and no agreed answer to what revenue means across entities. An agent querying through the Virtualize phase inherits enterprise-agreed definitions, entity relationships, and access controls. The architecture makes the correct answer the only possible answer.
The Virtualize phase produces a context layer the whole enterprise consumes from — enterprise BI, conversational AI, agentic workflows, and API consumers all read the same governed metric definitions, entity relationships, and access policies. The Gold-Platinum Data Contract makes that surface auditable regardless of the underlying tooling.
The architecture also extends naturally to emerging open semantic standards. The Open Semantic Interchange (OSI), co-developed by Snowflake, Databricks, dbt Labs, Salesforce, and others, is one such effort — a vendor-neutral YAML specification for metric and semantic definitions. Where organizations adopt OSI-compliant tools, the Platinum context layer extends to them.
The CDV Principle describes the architecture as it should work. The following blueprints address the real-world constraints that shape how it is implemented in the enterprises you actually operate in — with concrete implementation detail at every step. They are not presented in any particular order — each stands on its own and can be applied independently of the others.
The Virtualize phase connects to domain Gold data products. How it connects depends on what the platform stack currently supports. The architectural intent is always zero data movement — data stays where it lives and is read in place. But platform capabilities vary. Not every combination of platforms supports zero-copy federation today. The wrong mechanism choice creates either unnecessary data movement or a broken consumption surface. Choosing the right mechanism requires understanding what each one requires from the platform stack.
Evaluate three mechanisms in order of preference. Shortcuts first — storage-level federation. Both platforms access the same underlying storage. The Platinum semantic layer creates a pointer to the domain’s Delta or Iceberg table files. Zero data movement. The example below shows Fabric pointing to a Databricks-managed Delta table on ADLS Gen2; the same pattern applies to Snowflake-managed Iceberg tables, which Fabric reads through a OneLake shortcut with automatic Iceberg-to-Delta metadata virtualization.
📄 PLA-OBP-001-v01-virtualize-progressively.py
# Pragmatic Lakehouse Architecture — PLA Open Blueprint PLA-OBP-001-v01
# File: PLA-OBP-001-v01-virtualize-progressively.py
# DISCLAIMER: Illustrative sample only — not production-ready
#
# Shortcut — Example: Microsoft Fabric pointing to Databricks Delta on ADLS Gen2
# Configured in Fabric via the OneLake Shortcut UI or REST API
# No data movement — Fabric reads Delta files directly from ADLS Gen2
POST https://api.fabric.microsoft.com/v1/workspaces/{your-workspace-id}/items
{
"displayName": "gold_company_a_sales",
"type": "Shortcut",
"definition": {
"path": "Tables/sales_transactions",
"target": {
"type": "AdlsGen2",
"location": "abfss://gold-company-a@your-storage-account.dfs.core.windows.net",
"subpath": "sales_transactions" # Points to Delta table created by Databricks
}
}
}
Live federation second — protocol-level federation. No shared storage required. The Platinum semantic layer connects to the source platform through its native query protocol and reads at query time.
# Live Federation — Example: Fabric Platinum semantic model querying Snowflake Gold
# Direct Query at query time — no shared storage, rows fetched on demand
# The Platinum semantic model holds the metric definitions
# Snowflake serves the rows when a dashboard or AI agent queries
# Connection definition for the Fabric semantic model (TMSL / XMLA)
{
"createOrReplace": {
"object": { "database": "platinum_enterprise_model" },
"database": {
"name": "platinum_enterprise_model",
"model": {
"dataSources": [{
"name": "snowflake_domain_b_gold",
"connectionString":
"Provider=SNOWFLAKE;Server=your-account.snowflakecomputing.com;"
"Database=GOLD_DB;Schema=SALES;Warehouse=PLATINUM_WH;Role=PLATINUM_READER"
}],
"tables": [{
"name": "revenue_transactions",
"partitions": [{
"source": {
"type": "query",
"dataSource": "snowflake_domain_b_gold",
"expression": "SELECT * FROM gold.sales.revenue_transactions"
}
}],
"mode": "directQuery" # Federation — Snowflake answers at query time
}]
}
}
}
}
Governed replication last — when neither shortcut nor live federation is technically possible, replication is the fallback. Two paths are common: native mirroring where the platform supports it, or an ETL pipeline that materializes a physical Delta table in OneLake. Either way, a physical copy now exists — treat it as a managed exception, audit the scope, and plan to retire it as platform capabilities mature.
# Governed Replication — Two fallback patterns when shortcut and live federation are not possible
# Both create a physical copy in OneLake — treat as managed exceptions, not the default
# ─────────────────────────────────────────────────────────────────────────────
# Option A — Native mirroring: Snowflake → Fabric Mirrored Database
# Configured in Fabric via the Mirroring UI or REST API
# Continuous, near-real-time, zero pipeline code — but limited to what mirroring supports
# ─────────────────────────────────────────────────────────────────────────────
POST https://api.fabric.microsoft.com/v1/workspaces/{your-workspace-id}/mirroredDatabases
{
"displayName": "domain_b_snowflake_mirror",
"definition": {
"sourceType": "Snowflake",
"connection": {
"snowflakeAccount": "your-account.snowflakecomputing.com",
"database": "GOLD_DB",
"schema": "SALES"
},
"tables": ["REVENUE_TRANSACTIONS"], # Minimize scope — only what Platinum needs
"replicationMode": "continuous"
}
}
# ─────────────────────────────────────────────────────────────────────────────
# Option B — ETL into Fabric: materialize a physical Delta table in OneLake
# Use when mirroring is not supported, or when transforms/joins/filters are needed
# Pipeline can be Data Factory, a Spark notebook, or dbt on Fabric
# ─────────────────────────────────────────────────────────────────────────────
# Example: Spark notebook reading from Snowflake and writing to a Fabric lakehouse
df = (spark.read
.format("snowflake")
.options(**{
"sfURL": "your-account.snowflakecomputing.com",
"sfDatabase": "GOLD_DB",
"sfSchema": "SALES",
"sfWarehouse": "PLATINUM_WH",
"sfRole": "PLATINUM_READER"
})
.option("dbtable", "revenue_transactions")
.load())
# [IMPLEMENT] Optional transforms — projection, filtering, enrichment
# df = df.select("transaction_id", "amount", "currency", "transaction_date") ...
# Materialize as a physical Delta table inside OneLake
(df.write.format("delta")
.mode("overwrite")
.save("abfss://platinum@onelake.dfs.fabric.microsoft.com/replicated/revenue_transactions"))
# Note: a physical copy now exists in OneLake
# Document: why virtualization was not possible, scope, plan to retire
At enterprise scale, data products are consumed across zone boundaries by teams and systems that had no part in producing them. Any undocumented assumption about schema, quality, or delivery cadence becomes a silent dependency. When those assumptions break — and they do — the failure surfaces not at the source but at the dashboard, the report, or the AI agent that depended on it. The CDV Principle defines where the boundaries are. Data contracts make them enforceable.
In METAllion™, data contracts formalize the agreements at the two zone boundaries where ownership changes hands — one at the Copper-Silver boundary, one at the Gold-Platinum boundary. The Copper-Silver Data Contract is the single source of truth for what Copper guarantees and what Silver can depend on. It lives in git alongside the Copper pipeline code, versioned and shared with all domain teams that consume from Copper.
Two domain teams — Finance and Sales — each consume the same Copper output governed by the shared data contract. Both inherit Copper’s standardized foundation and proceed with their domain transformations without re-validating any field. Finance follows the Orchestrated pattern — its pipeline is triggered directly by Copper through Airflow when contract enforcement passes. Sales follows the Autonomous pattern — it runs on its own dbt schedule, checking the contract metadata table to determine whether new data is available before proceeding.
Contract definition
The YAML contract stored in git — the single source of truth for both Finance and Sales in this example. In organizations with mature enterprise catalogs, contracts are maintained and versioned there instead.
📄 PLA-OBP-002-v01-governing-zone-boundaries.yaml
# ================================================================================
# Pragmatic Lakehouse Architecture (PLA)
# PLA Open Blueprint: PLA-OBP-002-v01
# Title: Governing the Zone Boundaries
# File: PLA-OBP-002-v01-governing-zone-boundaries.yaml
# ================================================================================
# DISCLAIMER: This is an illustrative sample contract only.
# It is not production-ready. Adapt to your platform, tooling,
# and catalog maturity level.
# ================================================================================
sales_transactions_copper_silver_data_contract:
version: 1.0.0
producer: central-data-team
consumers: [finance-domain-team, sales-domain-team]
zone_boundary: copper_to_silver
effective_date: 2026-01-01
dataset:
name: copper.sales_transactions
refresh_cadence: daily
delivery_time: "06:00 UTC"
latency_tolerance: 30min
schema:
- field: transaction_id
type: string
nullable: false
classification: internal
- field: business_unit
type: string
nullable: false
classification: internal
master_data_validated: true # Validated against enterprise Business Unit master
- field: amount
type: decimal(18,2)
nullable: false
classification: confidential # Triggers column masking for unauthorized roles
- field: currency
type: string
nullable: false
classification: internal
reference_data_validated: true # Validated against enterprise currency reference list
- field: transaction_date
type: date
nullable: false
classification: internal
- field: recognition_policy
type: string
nullable: false
classification: internal
allowed_values: [ASC606, IFRS15] # Enforced by Copper custom rule library
change_policy:
notification_period: 30_days
versioning: semantic
breaking_changes_require: central_team_approval
deprecation_period: 60_days
Step 1 — Copper enforcement pipeline
The Copper pipeline loads the contract YAML as the source of truth, enforces all rules against the Bronze data, and writes one record to _contract_metadata on completion. The pipeline status — PASSED or FAILED — reflects the outcome of the entire run. What constitutes a failure threshold is a team decision; this example treats any rule violation as a FAILED status. Infrastructure failures are handled separately from contract status.
📄 PLA-OBP-002-v01-copper-contract-enforcement.py
"""
================================================================================
Pragmatic Lakehouse Architecture (PLA)
PLA Open Blueprint: PLA-OBP-002-v01
Title: Governing the Zone Boundaries
File: PLA-OBP-002-v01-copper-contract-enforcement.py
================================================================================
DISCLAIMER: This is illustrative skeleton code only. It is not production-ready.
Placeholder functions marked with [IMPLEMENT] require domain-specific
implementation based on your platform, tooling, and catalog setup.
================================================================================
Central team responsibility:
1. Load contract rules from YAML — single source of truth
2. Validate Bronze data per contract rules
3. Write enforcement result to _contract_metadata table
4. On PASSED — Copper output is ready for Silver consumption
5. On FAILED — Silver pipelines will not proceed
_contract_metadata table schema:
run_seq | bigint — auto-incremented per run
contract_name | string — references the YAML contract
contract_version | string — version declared in YAML
table_name | string — source table being enforced
status | string — PASSED or FAILED
enforced_at | timestamp — UTC timestamp of enforcement
row_count | bigint — rows processed
violation_count | bigint — number of rule violations found
"""
from pyspark.sql import functions as F
from pyspark.sql.types import *
from datetime import datetime
import yaml
# ── Configuration ─────────────────────────────────────────────────
CONTRACT_FILE = "sales_transactions_copper_silver_data_contract.yaml"
CONTRACT_NAME = "sales_transactions_copper_silver_data_contract"
CONTRACT_VERSION = "1.0.0"
TABLE_NAME = "sales_transactions"
BRONZE_PATH = "abfss://bronze@your-storage-account.dfs.core.windows.net/sales_transactions"
COPPER_PATH = "abfss://copper@your-storage-account.dfs.core.windows.net/sales_transactions"
METADATA_PATH = "abfss://copper@your-storage-account.dfs.core.windows.net/_contract_metadata"
METADATA_SCHEMA = StructType([
StructField("run_seq", LongType(), False),
StructField("contract_name", StringType(), False),
StructField("contract_version", StringType(), False),
StructField("table_name", StringType(), False),
StructField("status", StringType(), False),
StructField("enforced_at", StringType(), False),
StructField("row_count", LongType(), True),
StructField("violation_count", LongType(), True),
])
# ── Placeholder functions — [IMPLEMENT] per your platform ─────────
def load_contract(contract_file):
"""
[IMPLEMENT] Load contract YAML from git repository or catalog.
Returns contract dict with schema, quality, and change_policy rules.
"""
with open(contract_file, "r") as f:
return yaml.safe_load(f)["sales_transactions_copper_silver_data_contract"]
def apply_contract_rules(df, contract):
"""
[IMPLEMENT] Apply all enforcement rules driven by the contract YAML.
Rules include: schema enforcement, reference data validation,
master data validation, classification-driven security,
and custom rule library checks.
See Blueprint PLA-OBP-003-v01 for the implementation approach.
Raises ContractViolationError if any rule is violated.
Returns (df_copper, violation_count) on success.
"""
raise NotImplementedError("[IMPLEMENT] apply_contract_rules()")
def get_next_run_seq():
"""Get next sequence number from the metadata table."""
try:
df = spark.read.format("delta").load(METADATA_PATH)
return df.agg(F.max("run_seq")).collect()[0][0] + 1
except Exception:
return 1 # First run
def write_contract_metadata(run_seq, status, row_count, violation_count):
"""Write one contract execution record to the metadata table."""
record = [{
"run_seq": run_seq,
"contract_name": CONTRACT_NAME,
"contract_version": CONTRACT_VERSION,
"table_name": TABLE_NAME,
"status": status,
"enforced_at": datetime.utcnow().isoformat(),
"row_count": row_count,
"violation_count": violation_count
}]
spark.createDataFrame(record, METADATA_SCHEMA) \
.write.format("delta").mode("append").save(METADATA_PATH)
class ContractViolationError(Exception):
def __init__(self, message, violation_count):
super().__init__(message)
self.violation_count = violation_count
# ── Main Copper pipeline ───────────────────────────────────────────
def run_copper_pipeline():
"""
Runs Copper enforcement pipeline.
Returns run_seq on success — passed to Finance Silver via Airflow conf.
Raises ContractViolationError on contract failure.
All other exceptions propagate as pipeline errors, not contract failures.
"""
run_seq = get_next_run_seq()
# Load contract YAML — single source of truth
contract = load_contract(CONTRACT_FILE)
# Read Bronze data
df = spark.read.format("delta").load(BRONZE_PATH)
# Apply contract rules — raises ContractViolationError if rules not satisfied
# Any other exception propagates as a pipeline error, not a contract failure
try:
df_copper, violation_count = apply_contract_rules(df, contract)
except ContractViolationError as e:
# Only contract rule failures are recorded as FAILED status
write_contract_metadata(run_seq, "FAILED", df.count(), e.violation_count)
raise
# Write to Copper zone
df_copper.write.format("delta").mode("overwrite").save(COPPER_PATH)
# Write PASSED record — both Finance and Sales Silver depend on this
write_contract_metadata(run_seq, "PASSED", df_copper.count(), 0)
print(f"Contract {CONTRACT_NAME} v{CONTRACT_VERSION} PASSED. run_seq={run_seq}")
return run_seq
Step 2 — Airflow DAG for the Orchestrated pattern
The Copper pipeline runs on a daily schedule aligned to the contract delivery time. On success it triggers the Finance Silver DAG, passing the contract run sequence number so Finance knows exactly which enforcement record it is processing. Sales Silver is not triggered here — it checks the metadata table on its own schedule.
📄 PLA-OBP-002-v01-copper-airflow-dag.py
"""
================================================================================
Pragmatic Lakehouse Architecture (PLA)
PLA Open Blueprint: PLA-OBP-002-v01
Title: Governing the Zone Boundaries
File: PLA-OBP-002-v01-copper-airflow-dag.py
================================================================================
DISCLAIMER: This is illustrative skeleton code only. It is not production-ready.
================================================================================
Central team Airflow DAG:
- Runs Copper enforcement pipeline daily per contract SLA
- On success: triggers Finance Silver DAG (Orchestrated pattern)
- Does NOT trigger Sales Silver — Sales is Autonomous
- copper_run_seq is passed via conf so Finance Silver knows
exactly which contract record it is processing
"""
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.trigger_dagrun import TriggerDagRunOperator
from datetime import datetime
# Import Copper pipeline from enforcement module
from PLA_OBP_002_v01_copper_contract_enforcement import run_copper_pipeline
with DAG(
dag_id="copper_sales_pipeline",
schedule_interval="0 6 * * *", # Daily at 06:00 UTC — per contract delivery_time
start_date=datetime(2026, 1, 1),
catchup=False,
tags=["copper", "pla", "central-team"]
) as dag:
run_copper = PythonOperator(
task_id="run_copper_pipeline",
python_callable=run_copper_pipeline,
# Returns run_seq via XCom on success
# Raises exception on FAILED — downstream trigger will not fire
)
# Trigger Finance Silver immediately after Copper PASSED
# copper_run_seq passed via conf — Finance Silver uses this to identify
# which _contract_metadata record it is processing
trigger_finance_silver = TriggerDagRunOperator(
task_id="trigger_finance_silver",
trigger_dag_id="finance_silver_pipeline",
conf={"copper_run_seq": "{{ ti.xcom_pull(task_ids='run_copper_pipeline') }}"},
wait_for_completion=False, # Fire and proceed — Finance runs independently
)
run_copper >> trigger_finance_silver
# Sales Silver is NOT in this DAG — it runs Autonomously on its own schedule
Step 3 — Finance domain: Orchestrated Silver pipeline
The Finance Silver pipeline is triggered by the Copper DAG on successful contract validation. It reads the Copper output directly, trusts the contract enforcement, and applies Finance domain transformations — fiscal quarter treatment, inter-company elimination flags, and any other domain-specific business logic. It records the run sequence number it processed and never runs independently of Copper.
📄 PLA-OBP-002-v01-finance-silver-orchestrated.py
"""
================================================================================
Pragmatic Lakehouse Architecture (PLA)
PLA Open Blueprint: PLA-OBP-002-v01
Title: Governing the Zone Boundaries
File: PLA-OBP-002-v01-finance-silver-orchestrated.py
================================================================================
DISCLAIMER: This is illustrative skeleton code only. It is not production-ready.
Placeholder functions marked with [IMPLEMENT] require domain-specific
implementation based on your platform and tooling.
================================================================================
Finance domain — Orchestrated pipeline pattern:
- Triggered by Copper DAG on successful contract validation
- Receives copper_run_seq via Airflow conf
- Trusts Copper enforcement — no re-validation of any field
- Applies Finance domain transformations
- Updates its own last_processed_seq after successful run
- schedule_interval=None — never runs independently
"""
from airflow import DAG
from airflow.operators.python import PythonOperator
from pyspark.sql import functions as F
from datetime import datetime
COPPER_PATH = "abfss://copper@your-storage-account.dfs.core.windows.net/sales_transactions"
FINANCE_SILVER = "abfss://silver@your-storage-account.dfs.core.windows.net/finance/revenue"
FINANCE_META = "abfss://silver@your-storage-account.dfs.core.windows.net/finance/_domain_metadata"
CONTRACT_NAME = "sales_transactions_copper_silver_data_contract"
TABLE_NAME = "sales_transactions"
def apply_finance_transformations(df):
"""
[IMPLEMENT] Finance domain transformations.
Examples: fiscal quarter mapping, inter-company elimination flags,
currency normalization, recognition policy treatment.
"""
raise NotImplementedError("[IMPLEMENT] apply_finance_transformations()")
def update_domain_metadata(copper_run_seq):
"""Update Finance domain last_processed_seq after successful run."""
spark.createDataFrame([{
"domain": "finance",
"source_table": TABLE_NAME,
"contract_name": CONTRACT_NAME,
"last_processed_seq": int(copper_run_seq),
"processed_at": datetime.utcnow().isoformat()
}]).write.format("delta").mode("overwrite").save(FINANCE_META)
def run_finance_silver(**context):
# copper_run_seq passed by Copper DAG via Airflow conf
copper_run_seq = context["dag_run"].conf.get("copper_run_seq")
print(f"Finance Silver triggered by Copper. copper_run_seq={copper_run_seq}")
# Read Copper output — trust the contract, no re-validation
df_copper = spark.read.format("delta").load(COPPER_PATH)
# Apply Finance domain transformations
df_finance = apply_finance_transformations(df_copper)
# Write Finance Silver output
df_finance.write.format("delta").mode("overwrite").save(FINANCE_SILVER)
# Update Finance last_processed_seq
update_domain_metadata(copper_run_seq)
print(f"Finance Silver complete. copper_run_seq={copper_run_seq}")
# ── Finance Silver Airflow DAG ─────────────────────────────────────
with DAG(
dag_id="finance_silver_pipeline",
schedule_interval=None, # Only triggered by Copper — never runs independently
start_date=datetime(2026, 1, 1),
catchup=False,
tags=["silver", "finance", "pla", "orchestrated"]
) as dag:
run_finance = PythonOperator(
task_id="run_finance_silver",
python_callable=run_finance_silver,
provide_context=True,
)
Step 4 — Sales domain: Autonomous Silver pipeline
The Sales Silver pipeline runs entirely in dbt on its own schedule. A pre-hook macro checks the contract metadata table for any new PASSED record since the last processed run sequence. If new data is available, the dbt model reads from the Copper source and applies Sales domain transformations. A post-hook macro then records the run sequence that was processed. If no new record is found, the model exits gracefully and retries on the next scheduled run. No Airflow DAG is needed — Sales operates completely independently of Copper’s pipeline.
📄 PLA-OBP-002-v01-sales-silver-autonomous.sql
-- ================================================================================
-- Pragmatic Lakehouse Architecture (PLA)
-- PLA Open Blueprint: PLA-OBP-002-v01
-- Title: Governing the Zone Boundaries
-- File: PLA-OBP-002-v01-sales-silver-autonomous.sql
-- ================================================================================
-- DISCLAIMER: This is illustrative skeleton code only. It is not production-ready.
-- ================================================================================
--
-- Sales domain — Autonomous pipeline pattern using dbt
-- Runs on its own schedule — independent of Copper DAG
-- pre-hook: checks _contract_metadata for a new PASSED record
-- exits gracefully if no new record found
-- model: reads from copper.sales_transactions
-- post-hook: records the processed run sequence
-- ── Macro: pre-hook — contract status check ──────────────────────
{% macro check_copper_contract() %}
{% set contract_name = "sales_transactions_copper_silver_data_contract" %}
{% set contract_version = "1.0.0" %}
{% set table_name = "sales_transactions" %}
-- Get Sales domain last_processed_seq
{% set last_seq = run_query("
SELECT COALESCE(MAX(last_processed_seq), 0)
FROM silver.sales._domain_metadata
WHERE source_table = '" ~ table_name ~ "'
").rows[0][0] %}
-- Check for new PASSED record since last run
{% set result = run_query("
SELECT run_seq FROM copper._contract_metadata
WHERE contract_name = '" ~ contract_name ~ "'
AND contract_version = '" ~ contract_version ~ "'
AND status = 'PASSED'
AND run_seq > " ~ last_seq ~ "
ORDER BY run_seq LIMIT 1
") %}
{% if result.rows | length == 0 %}
{{ exceptions.raise_compiler_error(
"No new contract records since seq=" ~ last_seq ~ ". "
"Sales Silver will retry on next scheduled run."
) }}
{% else %}
{{ log("Contract PASSED. run_seq=" ~ result.rows[0][0] ~ ". Proceeding.", info=True) }}
{% endif %}
{% endmacro %}
-- ── Macro: post-hook — update last_processed_seq ─────────────────
{% macro update_last_processed_seq() %}
{% set contract_name = "sales_transactions_copper_silver_data_contract" %}
{% set table_name = "sales_transactions" %}
{% set copper_run_seq = run_query("
SELECT MAX(run_seq) FROM copper._contract_metadata
WHERE contract_name = '" ~ contract_name ~ "' AND status = 'PASSED'
").rows[0][0] %}
{% do run_query("
MERGE INTO silver.sales._domain_metadata AS target
USING (SELECT 'sales' AS domain,
'" ~ table_name ~ "' AS source_table,
'" ~ contract_name ~ "' AS contract_name,
" ~ copper_run_seq ~ " AS last_processed_seq,
CURRENT_TIMESTAMP AS processed_at) AS source
ON target.source_table = source.source_table
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
") %}
{{ log("Sales last_processed_seq updated to " ~ copper_run_seq, info=True) }}
{% endmacro %}
-- ── dbt model ─────────────────────────────────────────────────────
{{ config(
materialized = "table",
pre_hook = "{{ check_copper_contract() }}",
post_hook = "{{ update_last_processed_seq() }}"
) }}
SELECT *
FROM {{ source("copper", "sales_transactions") }}
-- [IMPLEMENT] Add Sales domain transformations here
Many organizations configure access controls independently at each layer — warehouse permissions at one zone, column masking at another, row-level security at yet another, and a completely separate access model at the BI layer. Each configuration is an opportunity for inconsistency. A field classified as sensitive at one layer may be accessible at another. A regulatory change requires updating four separate configurations instead of one. The Converge phase resolves this by making the classification at the source the single enforcement point for the entire downstream chain.
Classify every field in the enterprise catalog at Copper ingestion time. The classification drives enforcement downstream automatically — no zone configures access independently.
The pattern in PySpark. The sample below applies to a revenue transaction dataset with transactions across North America, Europe, and APAC, carrying two recognition policies and multiple currencies. Copper receives this from Bronze and enforces the enterprise standard before the domain team touches it.
Note: The following is sample code to illustrate the pattern. It is not production-ready. Better implementations may exist depending on your platform and tooling choices.
📄 PLA-OBP-003-v01-classify-once-enforce-everywhere.py
# Pragmatic Lakehouse Architecture — PLA Open Blueprint PLA-OBP-003-v01
# File: PLA-OBP-003-v01-classify-once-enforce-everywhere.py
# DISCLAIMER: Illustrative sample only — not production-ready
#
# Copper zone — schema enforcement + classification in one pass
# Both driven by the enterprise catalog, not hardcoded logic
from pyspark.sql import functions as F
from pyspark.sql.types import DecimalType
# Step 1 — Pull field classifications from enterprise catalog
catalog = get_catalog_classifications("sales_transactions")
# Returns: {"amount": {"type": "decimal(18,2)", "classification": "confidential"},
# "currency": {"reference_data": "iso_currencies"},
# "customer_name": {"classification": "pii"}, ...}
# Step 2 — Schema enforcement from catalog type definitions
df = df.withColumn("amount", F.col("amount").cast(DecimalType(18, 2)))
df = df.filter(F.col("currency").isin(get_reference_values("iso_currencies")))
df = df.filter(F.col("business_unit").isin(get_master_values("business_units")))
df = df.filter(F.col("recognition_policy").isin(["ASC606", "IFRS15"]))
# Step 3 — Classification-driven security applied at same layer
for field, meta in catalog.items():
if meta.get("classification") == "pii":
df = df.withColumn(field, F.sha2(F.col(field).cast("string"), 256))
elif meta.get("classification") == "restricted":
df = df.drop(field)
# Step 4 — Fail the pipeline on any violation before Silver receives the data
if df.filter(F.col("amount").isNull()).count() > 0:
raise ValueError("Copper contract violation — pipeline halted")
# Write to Copper — classification metadata travels with the Delta table
df.write.format("delta").mode("overwrite") \
.save("abfss://copper@your-storage-account.dfs.core.windows.net/sales_transactions")
In this example, schema enforcement and classification are applied in one Copper pass — clean types, validated reference data, security already applied before Silver receives the data. Copper teams may choose different approaches depending on their platform, tooling, and organizational structure. A regulatory change that reclassifies a field in the enterprise catalog updates one entry. Every downstream zone picks up the change on the next pipeline run.
With the Converge phase in place, domain teams inherit a clean, governed foundation rather than inheriting someone else’s inconsistencies. With the Diverge phase formalized through data contracts, domain data products become trustworthy for consumers who had no part in producing them. With the Virtualize phase, enterprise-agreed metric definitions and AI context exist as a governed surface — not negotiated at query time but encoded upstream.
The three blueprints in this article address the immediate implementation constraints: which virtualization mechanism to use given your platform stack, how to govern the zone boundaries through contracts at whatever level of tooling maturity you currently have, and how to classify once and propagate that classification through every downstream zone automatically. Each can be adopted independently. Each reinforces the others as the pattern matures.
The CDV Principle sets the philosophy. The blueprints make it implementable. The next installment in the series will continue along the same path — turning more of the architecture into patterns that can be picked up and applied directly.
Part 1 of this series — Pragmatic Lakehouse Architecture: A Governed, Interoperable, AI-Ready Enterprise Data Framework. Read on Medium
Open Semantic Interchange — Industry-wide specification effort to standardize semantic metadata exchange. open-semantic-interchange.org
Data contracts — Andrew Jones: andrew-jones.com · Chad Sanderson: dataproducts.substack.com
Code samples — All code snippets in this article are illustrative samples only. The PLA GitHub repository is the home for implementation code as it becomes available.
© 2026 Hari Abburu. METAllion™ is the author’s trademark. All rights reserved. Licensed under CC BY-NC 4.0.